Overview
This document discusses special considerations when working with the KONA XM™ device when flashed with the special “XM” firmware that supports multiple, continuous asynchronous DMA transfers.
As of SDK 17.5, only the Linux NTV2 kernel driver supports CNTV2Card’s streaming DMA APIs.
The SDK provides two demonstration programs that utilize the streaming DMA APIs:
- NTV2StreamPlayer Demo — a simple video-only player;
- ntv2streampreview — a Qt-based GUI program that captures and displays incoming video.
Installing the Hardware
The KONA XM™ must be installed in appropriate PCIe slots. The minimum requirements are a PCI Express Gen3 × 4 lane slot.
The card can operate with PCIe bus power when inserted into a 25-watt slot, or on external power via its ATX 6-Pin connector located on the back of the card. It automatically switches to external power when it’s connected and available.
Obtaining & Installing KONA XM Firmware
The KONA XM firmware can be downloaded from here:
https://github.com/aja-video/ntv2-firmware/blob/github-mirror/konax/konaxm.bit
To install the firmware, follow the “Flashing” Firmware instructions.
DMA Engines
The KONA XM™ firmware implements streaming DMA engines instead of the block mode engines used in other AJA devices and the KONA X™.
In current designs, all the DMA engines are either block mode or streaming — not mixed — but this may change in the future.
- Note
- Streaming currently only works with video. Thus DEVICE_ID_KONAXM cannot currently DMA audio or other ancillary data.
Streaming APIs
10 APIs were added to support konaxm:
Kernel Driver
Two new NTV2Messages were added to the NTV2 kernel driver to implement the new streaming functionality. The messages correspond to these user-space classes:
Streaming
Capture
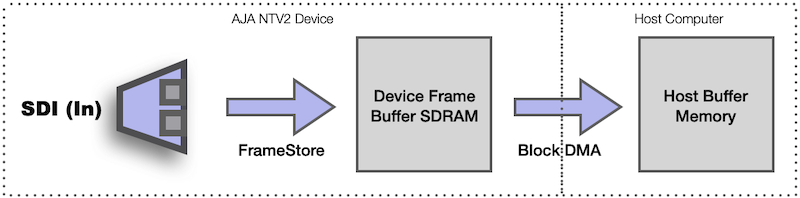
For capture, on all AJA devices except the KONA XM™, traditional AutoCirculate DMA transfers frame raster data from device SDRAM to host memory in a single frame-sized chunk:
In contrast, streaming mode captures directly to host memory:
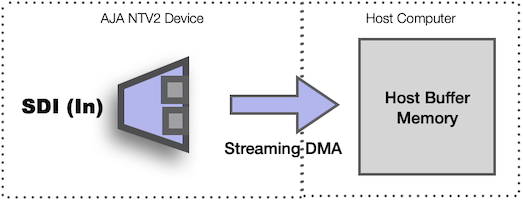
- Each FrameStore has a corresponding streaming DMA engine with the same channel number as the FrameStore.
- On KONA XM™, channels 1 and 3 are playback engines, and channels 2 and 4 are capture engines.
- Streaming DMA captures or plays video directly between host memory and the device crosspoint via the FrameStore.
- Routing and video processing with KONA XM™ firmware is the same as KONA X™ firmware.
- Since streaming DMA does not use device SDRAM, it therefore transfers continuously at the video pixel rate. This makes the synchronous AutoCirculate API impractical, so the streaming API uses a fully asynchronous design.
- Host buffers delivered to the AutoCirculate API are used to transfer data immediately at full PCIe transfer speed.
- Host buffers delivered to the streaming API are queued until the buffer is required by the streaming DMA engine, which operates at pixel rate, then released back to the application.
- Streaming playback requires buffers to be queued before playback can begin.
Playback
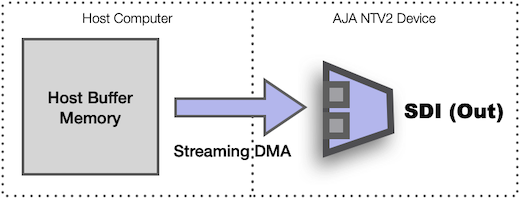
Streaming mode plays directly from host memory:
- Streaming mode playback requires transferring video to the device frame buffer before video playback can begin.
- Host buffers are queued to the driver to be used for transfers as the playback proceeds, and the application is notified when the buffers are released. This is similar to AutoCirculate DMA.
Details
- Streaming transfers are data agnostic.
- The application decides the size of the buffers to be transferred by the streaming DMA engine. The buffers can be the size of an entire video frame, multiple video frames, or a “slice” (sub-frame portion) of a video frame.
- The streaming DMA engine will start on the first video frame boundary following the call to CNTV2Card::StreamChannelStart.
- When the streaming engine starves, it cycles (repeats) on the last buffer in the queue until it receives a new buffer.
- Buffers must be locked (with the map flag) by the application before delivery to the streaming engine.
Latency
- The streaming DMA engine has the potential to deliver captured video to the application at lower latency.
- Currently AutoCirculate operates on video frames, and the capture latency is the time to capture the frame from the input to device SDRAM plus the DMA transfer time to host memory.
- The streaming latency for frame-size transfers is simply the time to capture the video from the input, since the capture occurs directly to the host buffer.
- The difference depends on the AutoCirculate DMA transfer time, which in most cases is much less than frame time.
- The streaming API has a real advantage if the application can operate on slices of a frame.
- Slices are delivered to host application memory as they arrive, and can be processed immediately without having to wait for the entire frame.
Streaming DMA Demos
There are two new demo apps that demonstrate streaming DMA.
NTV2StreamPlayer Demo
The NTV2StreamPlayer Demo operates just like the NTV2Player Demo but uses the streaming API instead of the AutoCirculate API.
- Note
- Streaming currently only supports video, so there is no audio or ancillary data.
- The significant changes are in the NTV2StreamPlayer::ConsumeFrames function, which has the same organization as NTV2Player Demo.
- The host buffers are prelocked then in a loop, then the current stream status is queried, buffers are queued to the stream from the circular list and released back to the circular list when their playout completes.
NTV2QtStreamPreview Demo
NTV2QtStreamPreview Demo operates just like NTV2QtPreview Demo but NTV2FrameGrabber uses the streaming API instead of AutoCirculate.
- The significant changes are in the NTV2StreamGrabber::run function, which locks and pre-queues host buffers, then a loop waits for captured buffers to be released, displays their contents in the application window, and re-queues them to be filled again.

 1.8.14
1.8.14